Recuperacion y Organizacion de la Informacion
Modelos de Recuperacion I
Modelo vectorial
En este modelo de recuperación de información, cada documento se representa a través de un vector de n dimensiones cuyas componentes son los términos que aparecen en el texto. El valor de cada componente se calcula a partir del IDF (Inverse Document Frequency) y se obtiene una representación vectorial para las consultas, que se comparan con los vectores de los documentos empleando una función de similitud. Para obtener la similitud entre un documento y su consulta se pueden utilizar algunas de las funciones siguientes:
Producto escalar:
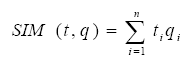
Distancia euclídea:
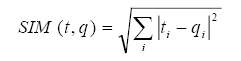
Fórmula del coseno:
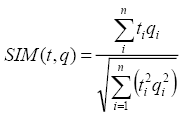
Entre las ventajas de este modelo de recuperación se encuentran:
-
Es posible obtener una lista ordenada de documentos que satisfacen la consulta.
- Es posible controlar la respuesta ante una consulta, ya sea limitando el número de resultados o estableciendo un umbral de similitud.
Como principal desventaja a destacar es que se supone que los términos de
indexación son independientes.





